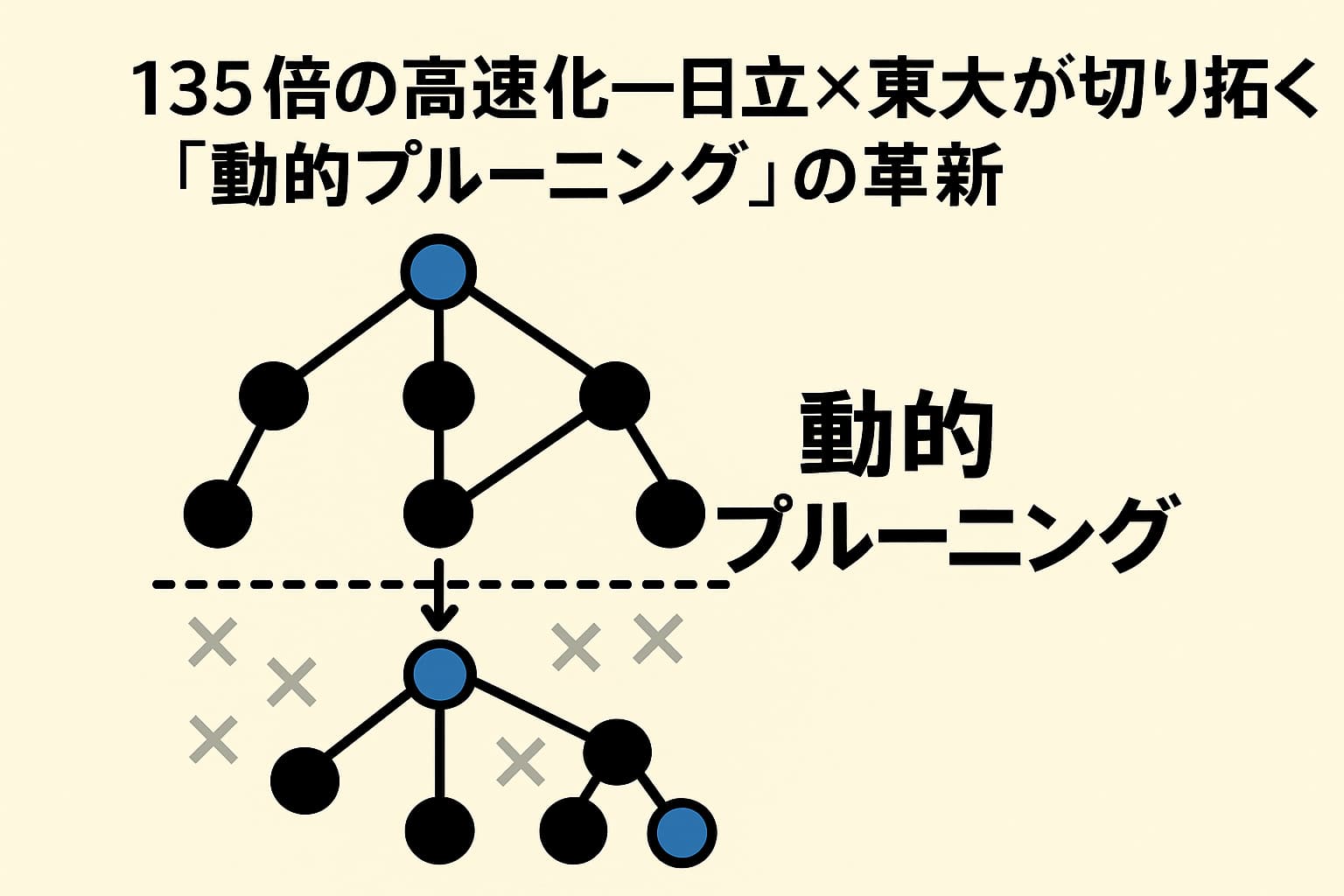
はじめに:探索空間の爆発と動的プルーニングの必然性
急速に膨張するビッグデータ社会では、グラフ構造を持つ膨大なデータの再帰検索や結合処理が一般化しています。しかしながら、高速化のボトルネックとなるのは、「探索の無駄」、すなわち成果が見込めないパスの延々と続く読み込みや計算です。特に再帰クエリは階層構造が深くなればなるほど検索空間が指数関数的に増加し、処理性能の限界に直面します。
そこで登場するのが「探索の価値」をリアルタイムに判断し、見込みの低い枝を早期に切り落とす技術―それが動的プルーニング(Dynamic Pruning)なのです。動作効率を飛躍的に高めつつ、リソース消費を抜本的に抑えるこの技術は、単なる高速化ではなく、「無駄を見抜く知性」が組み込まれた探索最適化方法といえます。
日立+東京大学がSIGMOD/PODS 2025で発表した新手法
2025年6月22〜27日、国際データベース会議SIGMOD/PODSの産業トラックでは、Hitachiと東京大学が共同で開発した技術が「Dynamic Pruning for Recursive Joins」として報告されました 。この共同研究では、
- 再帰的なJOIN処理中に中間到達結果をリアルタイムに取得し、
- そこからスコアや推定成功確率を算出し、
- 価値が小さい探索枝をその場で打ち切る
アルゴリズムを実装しています。
検証には製造業のトレーサビリティモデルが使われ、部品のステータスを辿って判断するクエリに対し、最大で135倍の高速化が確認されました。また、この技術はすでにHitachi Advanced Data Binder(HADB)に組み込まれており、Hitachi Intelligent Platformを通じた商用IoT基盤への実装も進行中です 。
動的プルーニングのコア技術
「実行時」を活かす賢さ
静的プルーニングは、クエリの最初の段階であらかじめ不要な枝を取り除くアプローチです。一方、**動的プルーニングでは処理の途中、実行時の状況に応じて「今この枝は動かす価値があるか」を判断します。**これにより、静的では捉えきれない情報を活用し、より効率的な探索が可能になります。
評価モデルの仕組み
具体的には以下の流れで処理されます:
- 中間到達ノードや深度などの情報を取得
- 経験的または統計的モデルによって、その枝が将来期待される成果の度合いを推定
- 成果推定値と探索コストを比較し、見込みが低い枝はリアルタイムで打ち切り
この判断プロセスはIoT環境など実運用でも非常に高速に動くよう設計され、ディスクI/O量・I/O回数が低減する結果、高速化につながります。
構造設計なくして動的プルーニングなし
インデックス・統計の埋め込みが不可欠
従来のB-treeやHashインデックスは一致検索には有効ですが、探索価値の予測には対応できません。動的プルーニングを実現するには、以下のような構造が必要です:
- 各ブロック・ノード・パーティションなどに最大スコア・min/max属性・頻度分布などの統計情報をあらかじめ保持すること
- 実行時にこれら統計値を活用して、枝の意義を判断可能にする
たとえば全文検索エンジンLuceneでは、BlockMax WANDにより各文書ブロックの最大スコア値を保持し、実行時に「このブロックは現在のスコアに届かない」と判断すれば即刻スキップする仕組みが採用されています 。
中間結果を取得するフック構造
再帰join処理では、中間状態の情報を取得するフックポイントが重要です。HADBやSpark Catalystのようなオプティマイザでは、JOIN処理のDo物理段階に入る直前で到達ノードや統計情報を取得し判断材料とします。この取得は軽量に設計されており、実行時のオーバーヘッドが最小限に抑えられます 。
製造業でのトレーサビリティクエリ具体例
動的プルーニングの効果が明確に証明されたのが製造業の部品追跡クエリです。たとえば、以下のように再帰的に部品の親子関係をたどり、不良品ステータスを持つものを除外するクエリでは、探索の枝が爆発的に増える可能性があります:
WITH RECURSIVE trace AS (
SELECT * FROM parts WHERE id = :root
UNION ALL
SELECT p.* FROM parts p
JOIN trace t ON p.parent_id = t.id
)
SELECT * FROM trace WHERE status = 'OK';
従来方式では膨大なノードを全探索し、I/Oや計算負荷が劇的に増加します。ところが動的プルーニングであれば、処理中に 「c→p間で子部品のステータスがOKにならない確率が高い」 と判断された枝を即座に切断。この結果、最大135倍の速度改善およびディスクアクセス削減を実現しました 。
他分野での動的プルーニング事例
■ Apache Spark Dynamic Partition Pruning(DPP)
Spark 3.0以降に導入されたDPPは、ジョイン処理時に小テーブル(Dimension)のフィルタ結果を動的に算出し、大テーブル(Fact)のパーティションスキャン対象を実行時に絞り込む仕組みです 。
たとえば以下のSQLにおいて:
SELECT o.customer_id, o.quantity
FROM Customers c
JOIN Orders o
ON c.customer_id = o.customer_id
WHERE c.grade = 5;
SparkはこのSQLを実行する際、Dimensionテーブルのgradeフィルタ結果をもとにBroadcast変数を作成。その結果、Ordersテーブルのパーティション列(customer_id)に対してIN (…)形式のサブクエリフィルタが実行時に挿入され、その後不要なパーティションは読み込み対象から除外されます。実際の実行プランには以下のような記述が現れます:
... PartitionFilters: [customer_id IN (broadcasted list)], dynamicPruningExpression: ...
この手法によって、たとえば100区画のParquetテーブルが10区画スキャンで済むようになり、I/O量が1/10に、実行時間も大幅に短縮されました 。
Sparkでのコード例
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")
# CustomersとOrdersテーブルを作成(ParquetファイルをPartitioned by customer_id)
spark.sql("""
CREATE TABLE Customers(id INT, grade INT) USING parquet
AS SELECT id, CAST(rand()*10 AS INT) AS grade FROM RANGE(100)
""")
spark.sql("""
CREATE TABLE Orders(customer_id INT, quantity INT)
USING parquet PARTITIONED BY(customer_id)
AS SELECT CAST(rand()*100 AS INT) AS customer_id,
CAST(rand()*100 AS INT) AS quantity
FROM RANGE(100000)
""")
# クエリを実行
res = spark.sql("""
SELECT o.customer_id, o.quantity
FROM Customers c JOIN Orders o
ON c.customer_id = o.customer_id
WHERE c.grade = 5
""")
res.collect()
計画には dynamicPruningExpression が現れ、実際に不要パーティションのスキップが適用されていることが確認できます 。
■ Lucene / Elasticsearch:BlockMax WAND
全文検索エンジンでは、探索候補のスコアを計算しながら「これ以上上位スコアになれないからこの範囲は飛ばす」という枝刈りが有効です。LuceneではBlockMax WANDというアルゴリズムにより、ポスティングリストをブロック単位に分割し、その最大スコアを保存。対象ブロックのスコア上限が現在の閾値を下回ると判断されれば、そのブロックをまるごとスキップします 。
この方法は、従来のMaxScoreやWANDよりも効率的な結果の取得を可能にし、ElasticsearchやWeaviateなどでも採用例があります 。
■ 機械学習モデルなどにおける枝刈り
XGBoostやRandom Forestのような決定木学習では、Early Stoppingという手法で検証誤差が改善しなくなった段階で学習を打ち切る動的プルーニングが取り入れられています。この判断も「将来の改善が見込めない探索枝」を除外するという点で同様の思想を持ちます。
将棋やチェスAIで使われるα‑βプルーニングも、葉ノードの推定評価を基に無意味な盤面を打ち切る技術であり、動的プルーニングの歴史的源流ともいえるでしょう。
成功要因と技術導入の鍵
このような技術が実効性を持つためには、以下のような要件を満たす構造設計と統計設計が不可欠です:
- 推定可能性:探索枝が将来的に成果を生む可能性を定量評価できる構造であること
- 統計付きインデックス:スコア・min/max・頻度などの情報を保持できる構造設計
- 中間取得可能性:探索処理中にリアルタイムで情報を抽出可能で、判断処理が軽量であること
- 実装効率:SparkやHADBのような計画最適化ステージへの密接な統合
- 汎用性:製造、検索、AI、BIなど多分野で再利用できる汎用探索最適化メカニズムであること
今後の展望:異分野融合とAI連携の可能性
動的プルーニング技術の今後には、以下のような展開が期待されます:
- 医療データ解析:診療トレースやリスクスコアリングにおける高速クエリ
- 金融セキュリティ:不正取引や相関関係の追跡にリアルタイム性が要求される場面
- AI連携:探索判断に機械学習モデルを組み合わせて予測精度を高める新たな枝刈り手法
- IoTプラットフォームの拡張:リアルタイム分析対象の爆増に対応し、探索負荷を制御
既にHADBやSparkに導入されたこの技術は、さらなる分野展開と最適化を視野に入れているため、今後も注目され続ける可能性が高いといえるでしょう。
終わりに:動的プルーニングという知的発見と、未来のデータ探索へ
データが爆発的に増加し続ける現代において、「すべてを見に行く」ことが必ずしも合理的でなくなる時代が到来しています。特に再帰的な構造やグラフ構造を持つデータに対しては、探索の範囲が広がれば広がるほど、その中に「本質的に無駄な探索」が潜んでいる可能性が高まります。動的プルーニングとは、そうした探索の“ムダ”を知的に見抜き、実行時に自律的に排除する技術です。
この手法は、単にSQLクエリや探索アルゴリズムの高速化手段という枠を超えて、「探索とは何か」「検索価値とは何か」という本質的な問いに対する解答でもあります。データベースにおける従来の最適化は、主に静的な情報に基づいていました。WHERE句、JOIN条件、インデックス設計、クエリプランの選択といったものは、いずれも「事前にわかっている情報」から導かれるものでした。
一方、動的プルーニングは、実行中に得られる“状況”をもとにして動作方針を変えていくという点で、まさに探索の意思決定が「動的=リアルタイムに変わっていく」設計思想を持っています。これはAI的とも言える視点であり、今後のデータ探索技術がより「文脈を読む」「流れを見極める」方向へ進化していくことを象徴しています。
このような先進的なアプローチが、日本企業と大学の連携によって誕生し、さらに国際会議での評価を受けていることは、世界的に見ても価値のある事例です。産業界からのフィードバックを受けてすでに実装と運用フェーズに入りつつある点も、理論倒れで終わらない「技術の現場適用モデル」として非常に重要です。
将来的には、AIによる探索価値のスコアリングや、推論ベースでのプルーニング判断など、「知的判断の自動化」がより洗練されることが予想されます。単なる枝刈りではなく、「探索の価値自体を定義し、評価し、選び取る」時代に向けて、動的プルーニングはその第一歩となるでしょう。
この技術は、我々が日々扱う膨大なデータの中から「本当に見るべきもの」だけを抽出するための、新しい視点と手段を与えてくれます。検索技術、意思決定、AI、インフラ、業務最適化など、あらゆる文脈でこのアプローチは応用可能です。単に速度を上げるのではなく、「考えながら探す」ための仕組み。それが動的プルーニングです。
今後、この技術がどのように深化し、他分野と融合していくかは、技術者にとっても研究者にとっても、非常に刺激的な未来への入り口となることでしょう。私たちは、探索の「賢さ」を設計する時代に生きているのです。
この記事を作成する際に参照した主要な情報源(参考文献)は以下の通りです。各文献のタイトルとURLをセットで記載しています。
参考文献一覧