Model loaded in 3.6s (load weights from disk: 0.3s, create model: 0.2s, apply weights to model: 1.8s, apply half(): 0.6s, load VAE: 0.1s, move model to device: 0.5s).
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 11.2s (import torch: 2.1s, import gradio: 1.7s, import ldm: 0.4s, other imports: 2.9s, load scripts: 0.3s, load SD checkpoint: 3.6s, create ui: 0.2s).
0%| | 0/20 [00:02<?, ?it/s]
Error completing request
Arguments: ('task(6gvckovujc9xon0)', 'sailing ship', '', [], 20, 0, False, False, 1, 1, 7, -1.0, -1.0, 0, 0, 0, False, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, [], 0, False, False, 'positive', 'comma', 0, False, False, '', 1, '', 0, '', 0, '', True, False, False, False, 0) {}
Traceback (most recent call last):
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/txt2img.py", line 56, in txt2img
processed = process_images(p)
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/processing.py", line 503, in process_images
res = process_images_inner(p)
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/processing.py", line 653, in process_images_inner
samples_ddim = p.sample(conditioning=c, unconditional_conditioning=uc, seeds=seeds, subseeds=subseeds, subseed_strength=p.subseed_strength, prompts=prompts)
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/processing.py", line 869, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 358, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 234, in launch_sampling
return func()
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 358, in <lambda>
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/sampling.py", line 145, in sample_euler_ancestral
denoised = model(x, sigmas[i] * s_in, **extra_args)
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 152, in forward
devices.test_for_nans(x_out, "unet")
File "/Users/t0k0sh1/Workspace/stable-diffusion-webui/modules/devices.py", line 152, in test_for_nans
raise NansException(message)
modules.devices.NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
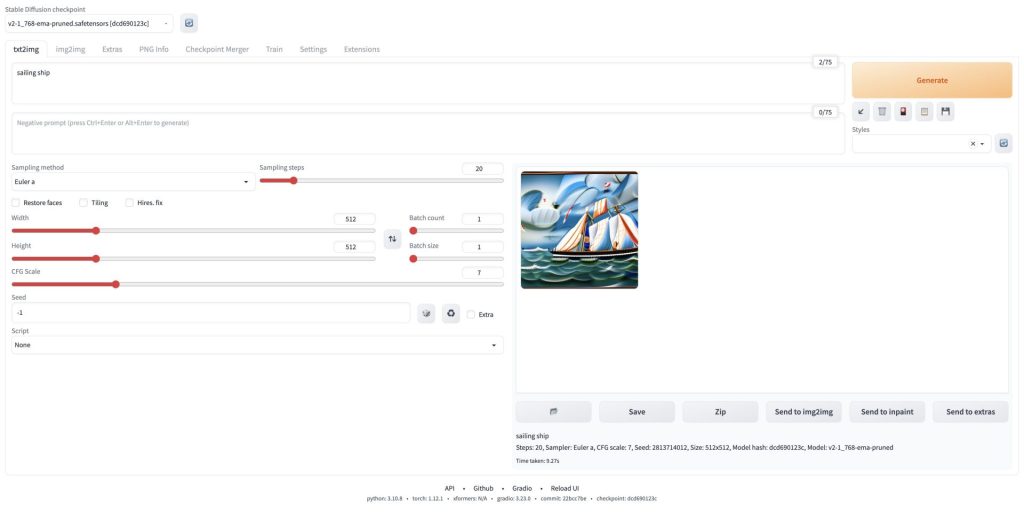
ちなみに、v1.4やv1.5ではこの事象は起きなかったので、v2.x系固有のエラーかもしれません。
これを解消するために、設定変更を行います。画面上部のタブからSettingsを選択し、
左のメニューからStable Diffusionを選択します。
バージョンにもよるかもしれませんが、一番下にUpcast cross attention layer to float32というチェックボックスがあるので、ここにチェックをつけてください。
package com.t0k0sh1.tutorial.entity;
import lombok.Data;
@Data
public class User {
private Long id;
private String name;
private String email;
private String password;
}
自動生成されているであろうgetterを使ってみます。
package com.t0k0sh1.tutorial.controller;
import com.t0k0sh1.tutorial.entity.User;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
@RestController
public class UserController {
private final List<User> users = new ArrayList<>();
@GetMapping("/users/{id}")
public User getUser(@PathVariable Long id) {
return users.stream().filter(a -> a.getId().equals(id)).findFirst().orElse(null);
}
}



































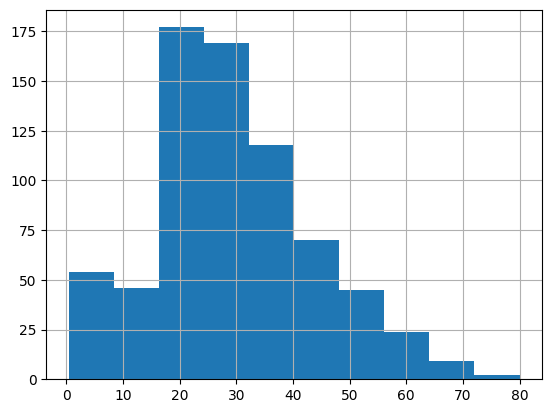
![[Pandas]代表値を求める(平均値、中央値、最頻値)](https://t0k0sh1.com/wp-content/uploads/2023/03/af6e09d2a56d3eb843c0eb67a53e7035.jpg)

![[Oracle]WITH句で階層問い合わせを行う](https://t0k0sh1.com/wp-content/uploads/2023/03/a6ac56027ff203bd46b3aaf610f9309a.jpg)
![[Spring Boot]IntelliJ IDEAでLombokを使っていてエラーになる場合の対処方法](https://t0k0sh1.com/wp-content/uploads/2023/03/4f99c13f66536d434005ad9be3c460c9.jpg)


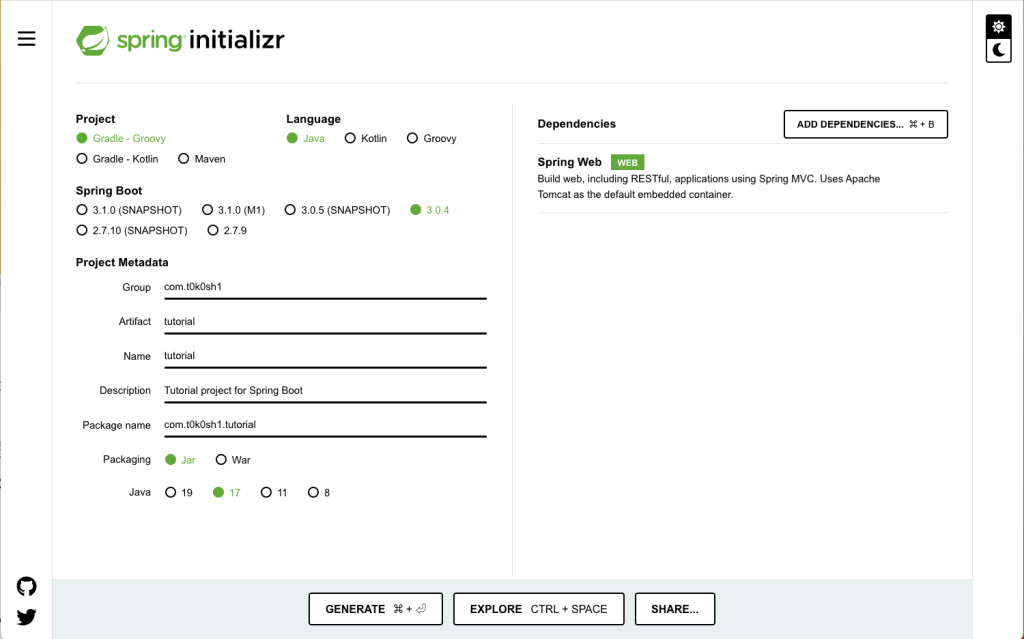
![[Spring Boot]プロジェクトを作成する(Spring Initializr)](https://t0k0sh1.com/wp-content/uploads/2023/03/8aff5dba3bb84fad0bb01b8f9773f756.jpg)




![[Oracle]ユーザー(スキーマ)を作成する](https://t0k0sh1.com/wp-content/uploads/2023/03/21350391f98f688d557ab99d8938a90b.jpg)