axiosでREST APIにアクセスするコードを含む複数のコードをtry-catchで囲んでいるときに、axiosのエラーをログなどに出力する際、JSON.stringifyしていたのですが、axios以外が原因でエラーになっている場合、JSON.stringifyでは文字列を得られなかったので対処方法を検討していました。
axios.isAxiosError
最初objectかどうかで判定しようとしていましたがうまく判定できませんでした。axiosではaxiosのエラーかどうかを判別するためのaxios.isAxiosErrorが提供されているため、これを使う方が良さそうです。
async function test() {
try {
const response = axios.get("http://httpstat.us/200");
} catch (error) {
if (axios.isAxiosError(error)) {
console.log(JSON.stringify(error, null, 2));
}
}動作確認
この動作を確認するために以下のようなプログラムで確認しました。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<script src="https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js"></script>
<script>
async function test() {
try {
const response = await axios.get("http://httpstat.us/200");
const a = [];
console.log(a[1].b);
} catch (error) {
if (axios.isAxiosError(error)) {
console.log("Axios Error:", JSON.stringify(error, null, 2));
} else {
console.log("Error:", String(error));
}
}
}
test();
</script>
</body>
</html>このプログラムでは、httpstat.usという指定したHTTPステータスのレスポンスを返してくれるサービスで任意のHTTPステータスを返すようにしています。HTTPステータスが200の場合は例外が発生しないため、後続の処理でundefinedなオブジェクトのプロパティにアクセスしているため例外が発生します。
上記のHTMLにブラウザからアクセスすると、コンソールログに
Error: TypeError: Cannot read properties of undefined (reading 'b')と表示されます。
一方、
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<script src="https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js"></script>
<script>
async function test() {
try {
const response = await axios.get("http://httpstat.us/404");
const a = [];
console.log(a[1].b);
} catch (error) {
if (axios.isAxiosError(error)) {
console.log("Axios Error:", JSON.stringify(error, null, 2));
} else {
console.log("Error:", String(error));
}
}
}
test();
</script>
</body>
</html>のようにURLの200部分を404に変えてアクセスすると、
Axios Error: {
"message": "Request failed with status code 404",
"name": "AxiosError",
"stack": "AxiosError: Request failed with status code 404\n at Qe (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:31804)\n at XMLHttpRequest.y (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:36641)\n at e.<anonymous> (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:48621)\n at p (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:3448)\n at Generator.<anonymous> (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:4779)\n at Generator.throw (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:3858)\n at p (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:9996)\n at u (https://cdn.jsdelivr.net/npm/axios@1.7.8/dist/axios.min.js:1:10235)",
"config": {
"transitional": {
"silentJSONParsing": true,
"forcedJSONParsing": true,
"clarifyTimeoutError": false
},
"adapter": [
"xhr",
"http",
"fetch"
],
"transformRequest": [
null
],
"transformResponse": [
null
],
"timeout": 0,
"xsrfCookieName": "XSRF-TOKEN",
"xsrfHeaderName": "X-XSRF-TOKEN",
"maxContentLength": -1,
"maxBodyLength": -1,
"env": {},
"headers": {
"Accept": "application/json, text/plain, */*"
},
"method": "get",
"url": "http://httpstat.us/404"
},
"code": "ERR_BAD_REQUEST",
"status": 404
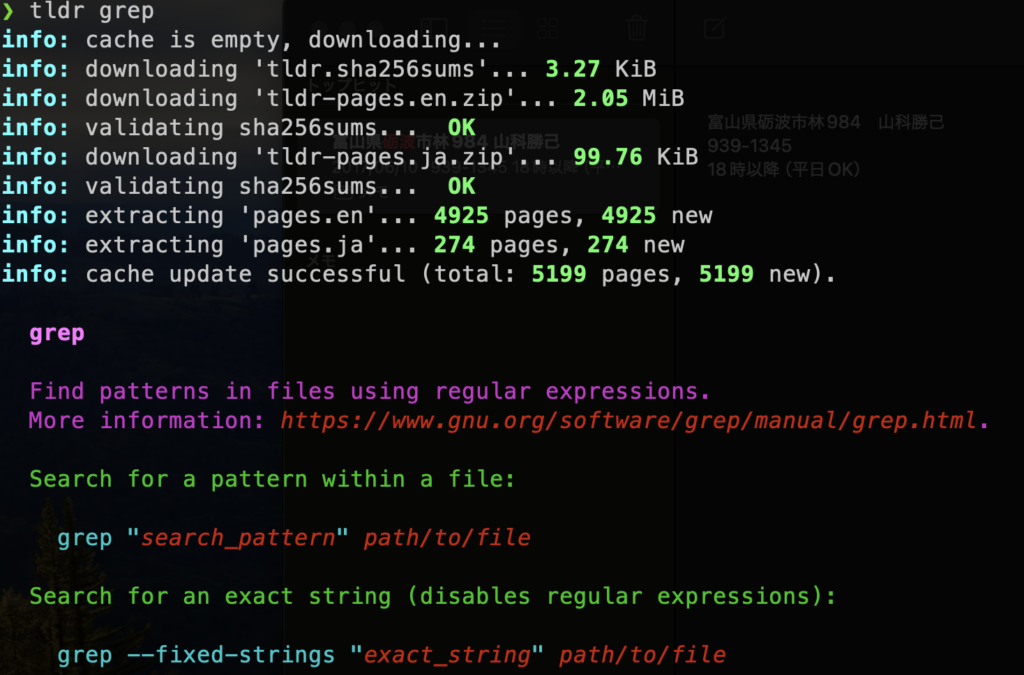
}と表示され、axios.isAxiosErrorでaxiosのエラーかどうかを判別できていることが確認できます。
まとめ
例外が発生したときにエラーページに遷移するという動作をするアプリケーションがあり、コンソールにログを出力しても記録に残らないため、サーバーにログが送るという対処を行っていました。実際に試してみると、axiosのエラーだと、エラーの内容がサーバーのログで確認できましたが、それ以外のエラーの場合は{}になって何も確認できないという事象があり、これを確認できるようにするために、このような検証をしてみました。
try-catchで例外をcatchしていることまでははっきりしていても、axiosのエラーかそれ以外のエラーかを判定する場合は型ではなく、axios.isAxiosErrorで判定するのが確実だということが確認できました。

















![[関係データベース]スーパーキー、候補キー、主キー、代替キー](https://t0k0sh1.com/wp-content/uploads/2024/09/8a9649b61b067e1ba8b9a32a1503bada.png)
![[PostgreSQL]外部キー制約を含むテーブルをDROPするとデッドロックが発生する](https://t0k0sh1.com/wp-content/uploads/2024/08/b250d97f825dd5349a2e27f5b16e83c0.png)
![[CSS]疑似クラス:first-child、:last-child、:nth-childを活用して特定の要素にスタイルを適用しよう](https://t0k0sh1.com/wp-content/uploads/2024/08/73776e0fefeb9471bac0e44294f49d7d.png)