![[Pandas]代表値を求める(平均値、中央値、最頻値)](https://t0k0sh1.com/wp-content/uploads/2023/03/af6e09d2a56d3eb843c0eb67a53e7035.jpg)
一般的によく知られている代表値といえば、平均値(mean)、中央値(median)、最頻値(mode)です。
Pandasを使ってこれらの値を求めてみます。
目次
下準備
今回はTitanicデータセットから年齢(Age)を使用します。
import pandas as pd
import math
df = pd.read_csv('./titanic/train.csv')平均値を求める
平均値を求めるにはmean()を使用します。
# 平均値(mean)を求める
df['Age'].mean()
# -> 29.69911764705882中央値を求める
中央値を求めるにはmedian()を使用します。
# 中央値(median)求める
df['Age'].median()最頻値を求める
最頻値を求めるには一工夫が必要です。最頻値は最も大きい度数の階級値になるため、一旦度数分布表を作成します。
ヒストグラムを確認する
度数分布表を作成する前にヒストグラムを確認しておきましょう。
df['Age'].hist(bins=10)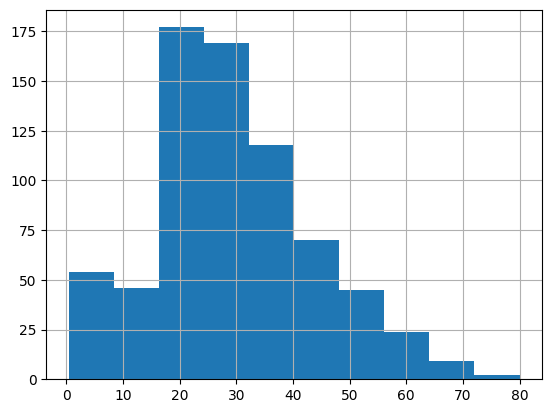
ビンの数を10に設定してヒストグラムを作成すると、20代が最頻値のようだということがわかります。
最頻値を求める
視覚的に確認できたところで、最頻値を求めます。度数分布表の作成方法はいくつかありますが、ここでは簡易的にcut()とvalue_counts()を組み合わせて、先ほど確認したグラフと同じ区間で度数分布表を作成します。
# 度数分布表を作成する
pd.cut(df['Age'], 10).value_counts()
---
(16.336, 24.294] 177
(24.294, 32.252] 169
(32.252, 40.21] 118
(40.21, 48.168] 70
(0.34, 8.378] 54
(8.378, 16.336] 46
(48.168, 56.126] 45
(56.126, 64.084] 24
(64.084, 72.042] 9
(72.042, 80.0] 2
Name: Age, dtype: int64作成した結果を確認しても20代が最頻値のようです。最頻値は区間の最小値と最大値の中間になりますので、$24.294-(24.294-16.336)\div2=20.315$となります。







