今回、Huskyを導入しますが、これにはトレードオフ(メリットとデメリット)があります。
メリット:
- コードの品質を保つ: Huskyはコードがリポジトリにコミットされる前に自動的にリントやテストを行うことができます。これにより、間違ったコードやコーディング規約に適合しないコードがマージされるのを防ぐことができます。
- 自動化: Huskyを設定することで、手動でリントやテストを行う手間を省くことができます。
- チームの一貫性: Huskyをプロジェクトに組み込むことで、全ての開発者が同じリントやテストを実行することを保証することができます。
デメリット:
- 初期設定の複雑さ: Huskyの設定は少々複雑であり、最初に設定する際には時間と労力が必要となります。
- 間違った設定による問題: Huskyが間違って設定された場合、全く関係のないファイルがコミットの対象になってしまったり、正常なコードでもコミットできなくなる可能性があります。
- コミットの遅延: もし大きなプロジェクトでテストが時間を要する場合、Huskyによりコミットが遅延する可能性があります。ただし、これは通常はリントやテストの速度問題であり、Husky自体の問題ではありません。
最も注意しなければならないのは、修正した箇所とは関係ない箇所でリントエラーが発生してコミットができないという自体が起こる可能性があるか、という点です。特に途中から導入する場合はリントエラーだらけでその対応に追われるということがあります。
リントエラーが解消したコードがコミットされることが理想的ではありますが、時と場合によってはそれよりもコミットすることが優先事項であることもありますし、プロジェクトの事情で修正箇所以外のエラーは一旦見なかったことにしたいということもあると思います。
また、コードベースが非常に大きく、リントに時間がかかってコミットがストレスになるというリスクもあります。こちらについては対策がありますので、併せてご紹介します。
Huskyとは
Huskyは、JavaScriptプロジェクトにおいてGitのフック(特定のGitイベントが発生した時に実行されるスクリプト)を簡単に管理できるようにするツールです。
Gitフックは、コミット、プッシュなどのGit操作の前後に自動的に実行されるスクリプトです。これを活用することで、コードの品質を一定に保つためのチェックやテストを自動化したり、特定の操作を制限したりすることが可能になります。
しかし、GitフックはGitリポジトリごとに設定され、通常はGitリポジトリ自体と一緒にバージョン管理されません。これは、他の開発者が同じフックを設定するのを難しくするだけでなく、フックの変更を追跡するのも困難にします。
Huskyはこれらの問題を解決します。Huskyを使用すると、フックはプロジェクトの一部としてバージョン管理でき、設定はすべての開発者間で共有できます。また、Huskyの設定は通常、プロジェクトのpackage.jsonファイルに記述され、設定の変更もGitを通じて追跡することができます。
このように、HuskyはJavaScriptプロジェクトにおけるGitフックの管理を効率化し、プロジェクト全体のコード品質を向上させる強力なツールとなることができます。
Huskyのインストール
まずはじめにHuskyをインストールします。
$ npm install husky --save-dev
added 1 package, and audited 1098 packages in 1s
165 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
インストール自体に難しいところはありません。
pre-commitフックを設定する
では早速pre-commitフックを設定しましょう。
$ npx husky install
husky - Git hooks installed
上記のコマンドを実行すると.huskyディレクトリが作成されます。
次にpre-commitフックを追加します。実行するコマンドは前回設定したnpm run lintにします。
$ npx husky add .husky/pre-commit "npm run lint"
husky - created .husky/pre-commit
では実際に実行してみましょう。Huskyをインストールしたときの変更のコミットがまだなので、これをコミットします。
$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: package-lock.json
modified: package.json
Untracked files:
(use "git add <file>..." to include in what will be committed)
.husky/
no changes added to commit (use "git add" and/or "git commit -a")
$ git add .
$ git commit -m 'install husky'
> angular-tutorial@0.0.0 lint
> ng lint
Linting "angular-tutorial"...
All files pass linting.
[main e0c8f78] install husky
3 files changed, 21 insertions(+)
create mode 100755 .husky/pre-commit
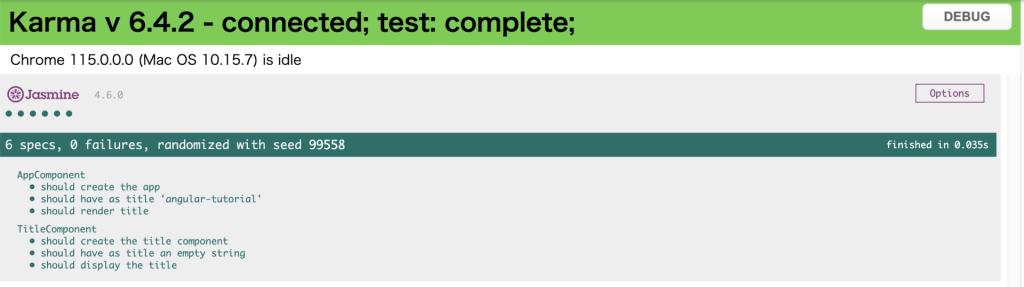
コミット時にリントが実行されていることが確認できます。
pre-commitフックでフォーマットを行う
次にpre-commitフックでPrettierを実行するようにしてみましょう。ついでに動作を確認もしてみます。
まず、Huskyのコマンドにはpre-commitフックを削除するコマンドがありません。では変更したい場合はどのようにするかを見ていきます。
現在の状態を確認する
まず、現在の状態はnpm run lintを設定してある状態です。
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npm run lint
ここに新たなコマンドを追加する場合は変わらずnpx husky addコマンドを使用します。
$ npx husky add .husky/pre-commit "npm run format"
husky - updated .husky/pre-commit
npx husky addコマンドを実行することで現在設定されているコマンドに加えて新たなコマンドがpre-commitフックに追加されます。
次にnpm run formatを削除してnpm run lintだけの状態にしてみます。これを実現するには、npx husky setコマンドを使用してnpm run lintを設定することでnpm run lintだけの状態になります。
$ npx husky set .husky/pre-commit "npm run lint"
husky - created .husky/pre-commit
このコマンドの実行するとnpm run lintだけになっていることが確認できます。
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npm run lint
最後にすべて削除する方法を確認します。先ほど使用したnpx husky setコマンドを使って削除ができます。
$ npx husky set .husky/pre-commit ""
husky - created .husky/pre-commit
上記コマンドを実行するとコマンドが削除されます。
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
pre-commitフックでlintとフォーマットの設定を行う
話を戻してpre-commitフックにnpm run lintコマンドとnpm run formatを設定します。npx husky addコマンドを2回呼び出してコマンドを追加します。
$ npx husky add .husky/pre-commit "npm run lint"
husky - updated .husky/pre-commit
$ npx husky add .husky/pre-commit "npm run format"
husky - updated .husky/pre-commit
これにより期待したとおりコマンドが登録されます。
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npm run lint
npm run format
では、動作確認をしていきます。.husky/pre-commitが変更されているのでこれをコミットすることで動作確認とします。
$ git add .
$ git commit -m 'update pre-commit hook'
> angular-tutorial@0.0.0 lint
> ng lint
Linting "angular-tutorial"...
All files pass linting.
> angular-tutorial@0.0.0 format
> prettier "src/**/*.{js,jsx,ts,tsx,html,css,scss}" --write
src/app/app.component.css 9ms
src/app/app.component.html 85ms
src/app/app.component.spec.ts 71ms
src/app/app.component.ts 3ms
src/app/app.module.ts 2ms
src/index.html 1ms
src/main.ts 2ms
src/styles.css 0ms
[main aeba2e0] update pre-commit hook
1 file changed, 2 insertions(+)
git commitをするとリントに続いてフォーマットが行われていることが確認できます。
リントおよびフォーマットの対象を限定する
現在は非常にコードが少ないためリントやフォーマットの時間がそれほどかかりません。ただ、実際のプロジェクトでは非常にたくさんのコードがある場合もあります。そのような場合、リントやフォーマットに時間がかかるだけでなく、対応した範囲とは関係ない箇所でエラーになってしまい、コミットがいつまでもできない、ということが起きることは容易に想像できます。
こういった問題を解決する一つの方法として、lint-stagedを導入します。
lint-stagedをインストール
普通のパッケージと同じようにインストールしていきます。
$ npm install --save-dev lint-staged
added 37 packages, and audited 1135 packages in 3s
180 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
lint-stagedを設定する
lint-stagedを設定していきます。まずはHuskyがpre-commitフックで実行するコマンドをnpx lint-stagedに変更します。
$ npx husky set .husky/pre-commit "npx lint-staged"
husky - created .husky/pre-commit
次にlint-stagedでnpm run lintコマンドとnpm run formatを実行するようにします。
{
"name": "angular-tutorial",
"version": "0.0.0",
"scripts": {
"ng": "ng",
"start": "ng serve",
"build": "ng build",
"watch": "ng build --watch --configuration development",
"test": "ng test",
"lint": "ng lint",
"format": "prettier \"src/**/*.{js,jsx,ts,tsx,html,css,scss}\" --write"
},
+ "lint-staged": {
+ "*.{js,jsx,ts,tsx}": [
+ "npm run lint"
+ ],
+ "*.{js,jsx,ts,tsx,html,css,scss}": [
+ "npm run format"
+ ]
+ },
"private": true,
"dependencies": {
"@angular/animations": "^16.1.0",
"@angular/common": "^16.1.0",
"@angular/compiler": "^16.1.0",
"@angular/core": "^16.1.0",
"@angular/forms": "^16.1.0",
"@angular/platform-browser": "^16.1.0",
"@angular/platform-browser-dynamic": "^16.1.0",
"@angular/router": "^16.1.0",
"rxjs": "~7.8.0",
"tslib": "^2.3.0",
"zone.js": "~0.13.0"
},
"devDependencies": {
"@angular-devkit/build-angular": "^16.1.6",
"@angular-eslint/builder": "16.1.0",
"@angular-eslint/eslint-plugin": "16.1.0",
"@angular-eslint/eslint-plugin-template": "16.1.0",
"@angular-eslint/schematics": "16.1.0",
"@angular-eslint/template-parser": "16.1.0",
"@angular/cli": "~16.1.6",
"@angular/compiler-cli": "^16.1.0",
"@types/jasmine": "~4.3.0",
"@typescript-eslint/eslint-plugin": "5.62.0",
"@typescript-eslint/parser": "5.62.0",
"eslint": "^8.44.0",
"eslint-config-prettier": "^8.9.0",
"husky": "^8.0.3",
"jasmine-core": "~4.6.0",
"karma": "~6.4.0",
"karma-chrome-launcher": "~3.2.0",
"karma-coverage": "~2.2.0",
"karma-jasmine": "~5.1.0",
"karma-jasmine-html-reporter": "~2.1.0",
"lint-staged": "^13.2.3",
"prettier": "^3.0.0",
"typescript": "~5.1.3"
}
}
"lint-staged"がコマンドの設定を行っている箇所です。リントとフォーマットで対象としたいファイルが異なるため分けて設定しています。
pre-commitフックを確認するまえに、npx lint-stagedコマンドを実行して動作を確認してみましょう。
$ npx lint-staged
→ No staged files found.
ステージされているファイルが何もないため、処理が行われませんでした。
では、現在変更されているコードをステージしてから実行してみましょう。
$ npx lint-staged
→ No staged files match any configured task.
少しメッセージが変わりました。ステージされているファイルはありましたが、条件にマッチするファイルがなかったため、処理が行われませんでした。
では、1つだけ処理対象となるファイルを変更してステージして動作を確認してみましょう。
import { Component } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css'],
})
export class AppComponent {
title = 'angular-tutorial';
}
app.component.tsを以下のように変更します。
import { Component } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css'],
})
export class AppComponent {
* title = 'angular-tutorial1';
}
titleをちょっとだけ変更しています。
変更をステージして実行してみます。
$ git add .
$ npx lint-staged
✔ Preparing lint-staged...
❯ Running tasks for staged files...
❯ package.json — 4 files
❯ *.{js,jsx,ts,tsx} — 1 file
✖ npm run lint [FAILED]
✔ *.{js,jsx,ts,tsx,html,css,scss} — 1 file
↓ Skipped because of errors from tasks. [SKIPPED]
✔ Reverting to original state because of errors...
✔ Cleaning up temporary files...
✖ npm run lint:
Error: Invalid values:
Argument: project, Given: "/Users/t0k0sh1/Workspace/angular-tutorial/src/app/app.component.ts", Choices: "angular-tutorial"
> angular-tutorial@0.0.0 lint
> ng lint /Users/t0k0sh1/Workspace/angular-tutorial/src/app/app.component.ts
実行したところエラーになりました。
結論からいうと、lint-stagedに指定したコマンドが原因です。リントを行うためにeslintを使用しているのではなく、ng lintを使用しています。
ng lintはプロジェクト全体に対して実行するコマンドのため、ステージしたファイルに対して限定的に使用することができません。ですので、少しコマンドを変更します。
{
"name": "angular-tutorial",
"version": "0.0.0",
"scripts": {
"ng": "ng",
"start": "ng serve",
"build": "ng build",
"watch": "ng build --watch --configuration development",
"test": "ng test",
"lint": "ng lint",
"format": "prettier \"src/**/*.{js,jsx,ts,tsx,html,css,scss}\" --write"
},
"lint-staged": {
"*.{js,jsx,ts,tsx}": [
* "eslint --fix"
],
"*.{js,jsx,ts,tsx,html,css,scss}": [
"npm run format"
]
},
"private": true,
"dependencies": {
"@angular/animations": "^16.1.0",
"@angular/common": "^16.1.0",
"@angular/compiler": "^16.1.0",
"@angular/core": "^16.1.0",
"@angular/forms": "^16.1.0",
"@angular/platform-browser": "^16.1.0",
"@angular/platform-browser-dynamic": "^16.1.0",
"@angular/router": "^16.1.0",
"rxjs": "~7.8.0",
"tslib": "^2.3.0",
"zone.js": "~0.13.0"
},
"devDependencies": {
"@angular-devkit/build-angular": "^16.1.6",
"@angular-eslint/builder": "16.1.0",
"@angular-eslint/eslint-plugin": "16.1.0",
"@angular-eslint/eslint-plugin-template": "16.1.0",
"@angular-eslint/schematics": "16.1.0",
"@angular-eslint/template-parser": "16.1.0",
"@angular/cli": "~16.1.6",
"@angular/compiler-cli": "^16.1.0",
"@types/jasmine": "~4.3.0",
"@typescript-eslint/eslint-plugin": "5.62.0",
"@typescript-eslint/parser": "5.62.0",
"eslint": "^8.44.0",
"eslint-config-prettier": "^8.9.0",
"husky": "^8.0.3",
"jasmine-core": "~4.6.0",
"karma": "~6.4.0",
"karma-chrome-launcher": "~3.2.0",
"karma-coverage": "~2.2.0",
"karma-jasmine": "~5.1.0",
"karma-jasmine-html-reporter": "~2.1.0",
"lint-staged": "^13.2.3",
"prettier": "^3.0.0",
"typescript": "~5.1.3"
}
}
実行するコマンドをnpm run lintからeslint --fixに変更しました。変更したついでに--fixオプションをつけて修正もできるようにしてあります。
再度実行してみましょう。
$ npx lint-staged
✔ Preparing lint-staged...
✔ Hiding unstaged changes to partially staged files...
✔ Running tasks for staged files...
✔ Applying modifications from tasks...
✔ Restoring unstaged changes to partially staged files...
✔ Cleaning up temporary files...
今度はすべて成功しています。
最後にコードを整理してコミット&プッシュ
app.component.tsに加えた変更は不要なので、戻しておきます。
$ git restore --staged src/app/app.component.ts
$ git checkout -- src/app/app.component.ts
それ以外の変更は正式に採用するので、ステージしてコミットし、これまでの変更も含めてプッシュしておきます。
$ git add .
$ git commit -m 'set up husky and lint-staged'
→ No staged files match any configured task.
[main 58ad1f8] set up husky and lint-staged
3 files changed, 504 insertions(+), 3 deletions(-)
$ git push
Enumerating objects: 19, done.
Counting objects: 100% (19/19), done.
Delta compression using up to 10 threads
Compressing objects: 100% (13/13), done.
Writing objects: 100% (16/16), 5.23 KiB | 892.00 KiB/s, done.
Total 16 (delta 7), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (7/7), completed with 3 local objects.
To github.com:t0k0sh1/angular-tutorial.git
f20d6df..58ad1f8 main -> main
まとめ
少し長くなりましたが、Huskyとlint-stagedを導入してリントとフォーマットをpre-commitフックで実行できるようになりました。
もう少し設定が必要ですが、それは必要になったときに設定することとします。
開発を行う前に結構時間がかかりましたが、こういった設定は最初の段階で整備しておいた方がよいです。開発途中で導入しようとすると、これまでの分の修正に追われ、本来やるべきことに集中できなくなりますので、最初に説明しました。
次回はTailwind CSSを導入してコンポーネントを作成してみたいと思います。